
経営においても技術開発においても、数値シミュレーションは多く利用される。実際に計算したり、あるいは、結果を経営や技術開発の意思決定に用いた経験のある方も多いだろう。
気候変動の予測もシミュレーションが利用されているが、それはどのようなものであり、どの程度予言能力があるのだろうか?
地球温暖化問題を議論するとき、普通の人々は、モデル計算による温度上昇のシミュレーションを科学計算に基づく予測だと思って受け入れている。だがじつは、シミュレーションは物理学や化学の基礎方程式をそのまま直接に解いたものではない。モデルには任意性のあるパラメーターが多数設定されており、CO2等の濃度上昇に対して地球温暖化がどの程度になるか、結果を見ながらチューニング(=調整)されている。このことはあまり公の場で語られてこなかったが、近年になって、一部の有力な研究者が公表するようになった。以下に詳しく紹介しよう。
1.地球気候モデルとはどのようなものか
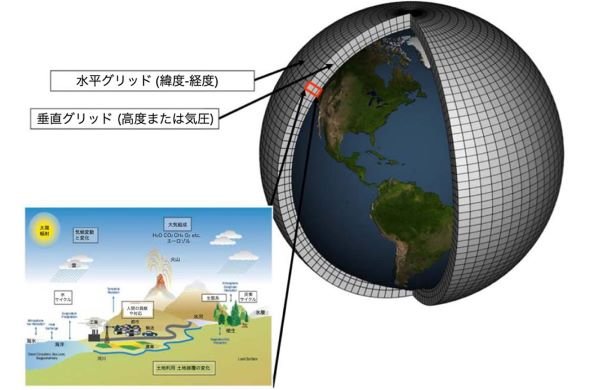
図1 地球気候モデルの概念図(Curry 2017)
地球気候モデルとは、コンピュータを使って地球気候システムのシミュレーションをするものだ(図1)。GCMには大気、海洋、地表、海氷、氷床をモデル化したモジュールがある。大気モジュールは⾵、温度、湿度、大気圧の推移を計算する。GCMにはまた、海洋の水循環、それが熱をどう運ぶか、海洋が大気と熱や湿気をどうやりとりするかを表す数式もある。地表モジュールは、植生、土壌、雪や氷による被覆が、大気とエネルギーや湿度をどうやりとりするかを記述する。海氷や氷床のモジュールもある。モデルの数式の⼀部は、ニュートンの運動法則や熱力学第⼀法則といった物理法則に基づいているが、主要プロセスの中には、物理法則に基づかない近似もある。
コンピュータでこうした⽅程式を解くため、GCMは大気、海洋、陸地を三次元のグリッドに切り分ける。そしてグリッドのそれぞれのセルごとに⽅程式が計算される。これがシミュレーション期間の時間ステップについて繰り返される。グリッドとセルの数が、モデルの解像度を決める。GCMで⼀般的な解像度は、⽔平⽅向25-300km、垂直⽅向は1km、時間ステップは30分ごとであるが、これは年々高くなっている。
とは言え、モデルの空間的・時間的解像度は現実の気候系と比べるとかなり粗い。そして、重要なプロセス(たとえば雲の形成や降⾬の発生)はモデルの解像度より小さい規模で起こる。こうしたグリッドのサイズ以下の物理的・化学的なプロセスは、実際のプロセスを近似しようとする、割と簡単な数式で表現される。それは実測に基づいたり、もっと詳細なプロセスモデルから導かれたりする。そこでは多くのパラメーターが設定される。そして、そのパラメーターは、過去の観測値と気候モデルの出力を近づけるために「チューニング」される。
GCM で使われる数式は、気候系における物理的・化学的プロセスの近似でしかなく、こうした近似の⼀部はどうしても粗雑になる。この理由は、プロセスが科学的によく分かっていなかったり、観測データが不足していたり、コンピュータの計算能力に限界があったりするためだ。
2.チューニングの実態が公表されるようになった
モデルのチューニングについて、研究者はあまり公の場で語ってこなかったが、近年になって、この業界の有力な研究機関の研究者たちが、その実態について発表するようになった。
2016年、論文誌サイエンス紙上で、「気候科学者、ブラックボックスを開いて検討にかける」という記事が掲載された(Voosen 2016)。ドイツのマックス・プランク研究所、米国の地球物理流体力学研究所など、気候モデル業界においてもっとも有力な研究機関の研究者たちの情報提供に基づくもので(Hourdin et. al. 2017)、概要は以下の通りだ。
- 「チューニング」という慣行が気候モデル業界に存在する。
- モデル研究者はチューニングをできるだけ少数のパラメーターの調節に制限しようと努力するが、思うように減らすことはまず出来ない。
- チューニングは科学でもあるが、職人技(art)でもある。「それは、音の悪い楽器を調整するようなものである」。
- 「すべてのモデルがチューニングされている」。研究者が認めるか否かにかかわらず、ほぼすべてのモデルは20世紀後半の地球温暖化を再現するようにチューニングされている。
- チューニングについて語ることは長い間タブーだった。それは、本当のことを語ると「人為的温暖化説に懐疑的な人々に付け込まれる」との恐れによるものだった。しかし一部の研究者たちは、チューニングをどのように行ったのか、その手続きを公開することが適切と考えた。理由は3つで、
- 透明性を高めることはモデルの改善に役に立つ
- 環境影響の研究者にとって、モデルの出力結果がプロセスの計算によるものなのかチューニングのせいなのかを知ることは大事である
- モデルの結果は政策決定に利用されるから、チューニングの実態を明らかにしたほうがよい
といったことだ。
3.雲のパラメーターについてのチューニングの事例
チューニングの実態についてもっとも顕著な例を紹介しよう。ドイツのマックス・プランク研究所のモデルには、雲の対流に関する「巻き込み」のパラメーターがあった(図2)。このパラメーターの設定次第で、周囲から空気を巻き込まず雲が高く発達する(左)か、周囲から空気を巻き込むので雲が発達しない(右)か、何れかのモデルになる。このパラメーターは理論や観測で十分に範囲を絞ることができず、設定に任意性があるものだった。
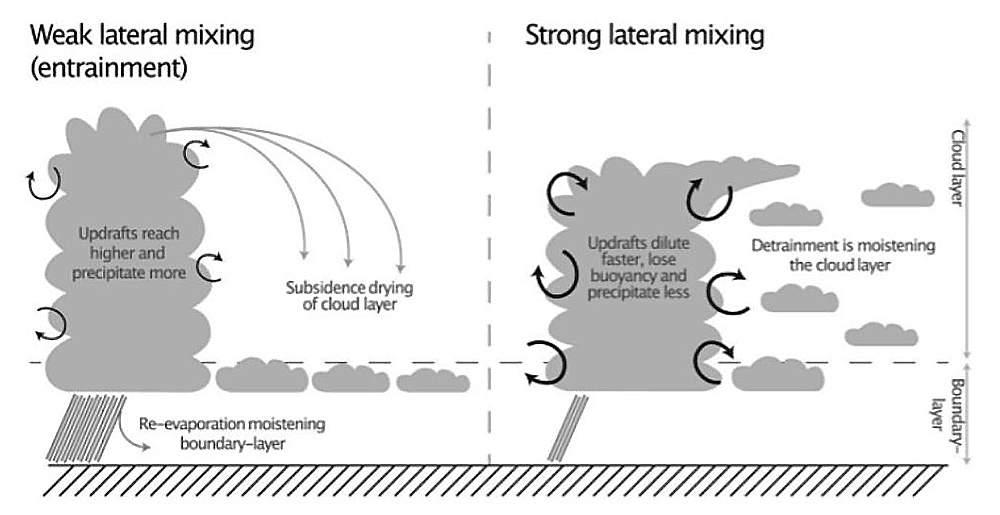
図2 雲の対流に関する「巻き込み」のパラメーターの効果。
左:弱い横混合(巻き込み)の場合。雲は高く発達し、降水は多くなる。下降気流によって雲層は乾燥化し、再蒸発で境界層は湿潤化する。
右:強い横混合(巻き込み)の場合。雲は高く発達しない。降水は少くなる。横混合によって雲層は湿潤化する。(Mauritsen et.al.2020)
このグループは、以前の論文では気候感度(=CO2濃度が産業革命前の280ppmから560ppmに倍増した場合の平衡状態における地球平均の温度上昇。気候モデルのCO2濃度に対する感度を特徴づける指標としてよく使用される)が3.5℃としていた(図3のバージョン1)。
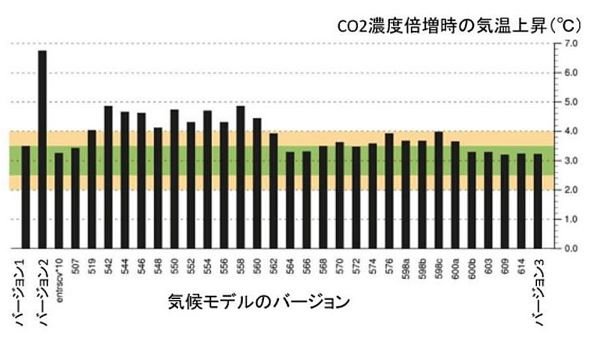
図3 気候モデルのチューニング(Mauritsen et al 2020)
ところが、その後、モデルにおける別のプロセスを改善したところ、気候感度がそれまでの3.5℃から7.0℃近くに倍増してしまった。そこでどうしたかというと、前述の雲の対流のパラメーターを「チューニング」して値を10倍変えて、気候感度を3℃近くに下げた(図3のバージョン2)。他にも様々なパラメーターを調整して多くのバージョンのモデルを作り、最終的に図3のバージョン3が次の論文として発表された。この過程においては、気候感度を3℃前後にすることをはっきりと目標にしてチューニングを行った、という。
IPCC報告では、20世紀後半に観測された地球の平均気温上昇と、モデルが示す温室効果ガスによる温度上昇が⼀致した、としている。このことは、地球温暖化の原因が温室効果ガスであることの証拠として紹介される。しかしこれだけでは、観測された気温の上昇の原因が温室効果ガスによるものだという証拠には、論理的に言って、ならない。というのは、モデルは、温度上昇が温室効果ガスによるものだとチューニングによって教え込まれているだけの可能性があるからだ
実際のところ、20世紀後半に起きた地球の平均気温上昇には、温室効果ガス以外の自然変動(エルニーニョのような海洋や大気の自律的振動や、太陽活動の変化)による影響が大きかったのかもしれない。地球の平均気温推計には都市熱もかなり混入している可能性も指摘されている。すると、それにチューニングしたモデルでは、温室効果ガスによる温暖化の効果は過大評価されていたのかもしれない。
4.チューニングした計算結果をどう解釈するか
このようにチューニングされたモデルの計算結果をどう解釈するか。チューニングは、科学的理解や観測データの欠如も多いとはいえ、膨大な観測データに整合するようにモデルが構築された結果だと解釈すれば、その予測についても、現状で入手できるデータに基づいた、最善を尽くした予測だ、と論じることも出来よう。
しかしその一方で、最も重要な指標である気候感度(これは21世紀の気温上昇予測に決定的に影響する)がチューニングの主な対象になっていて、しかもその数値がチューニングに大きく依存して決定されることには、おおいに注意が必要だ。
それに、過去についていくら合わせたところで、将来についての予測があたる保証にはならない。統計学的に「過学習」に陥ってしまっている可能性がある。一応過去を再現するが、その理由は「2回間違ったので帳消しになって合っている」といった状態になることだ。これだと将来の予測については全く当たらなくなる。
通常の技術開発のシミュレーションでは、理論や実験式に基づいてモデルを作った後で、実験と徹底的に突き合わせてその動作を確認するのが普通だ。しかもその動作が保証される時間的・空間的・物理化学的な条件などの範囲ははっきりと定められている。だが気候モデルはそうなっていない。過去の再現ですらあまりよくできていないから、まして、それが何十年後という将来についての動作が保証できるようなものにはなっているとは考えにくい。
気候のシミュレーションは技術よりもむしろ経済のシミュレーションに似ている。経済のシミュレーションでも理論や過去のデータの計測に基づいてモデルの構築をする。だがそれで精度よい予測が出来るか、というとまず出来ない。経済のシミュレーションは何かを予測するために作るというよりは、問題を理解するための手法であると考えた方がよい。気候のシミュレーションもそのようなものだと理解するならば間違いなく意義がある。とりあえずの知見を用いてシミュレーションをしてみるという訳だ。だがチューニングを用いたモデルに予言能力があるか、まして莫大な費用のかかる政策決定に使えるか、となると甚だ疑わしい。
米国の科学者スティーブン・クーニンは、チューニングに基づく予測は、捏造である、と批判している。そこまで言わずとも、政策決定に使われることを知りながら、チューニングの実態を詳らかにすることなくシミュレーションの予測結果を発表することは、科学と政治の関係として適切とは言い難い。科学者はチューニングの実態をもっとよく説明すべきであるし、政策決定はチューニングの実態をよく理解した上で行うべきだ。
〈参考文献〉
- Mauritsen, T., & Roeckner, E. (2020). Tuning the MPI-ESM1.2 Global Climate Model to Improve the Match With Instrumental Record Warming by Lowering Its Climate Sensitivity. Journal of Advances in Modeling Earth Systems, 12(5). https://doi.org/10.1029/2019MS002037
https://agupubs.onlinelibrary.wiley.com/doi/full/10.1029/2019MS002037 - Hourdin, F., Mauritsen, T., Gettelman, A., Golaz, J. C., Balaji, V., Duan, Q., Folini, D., Ji, D., Klocke, D., Qian, Y., Rauser, F., Rio, C., Tomassini, L., Watanabe, M., & Williamson, D. (2017). The art and science of climate model tuning. Bulletin of the American Meteorological Society, 98(3), 589–602. https://doi.org/10.1175/BAMS-D-15-00135.1
https://journals.ametsoc.org/view/journals/bams/98/3/bams-d-15-00135.1.xml - Voosen, P. (2016). Climate scientists open up their black boxes to scrutiny. Science, 354(6311), 401–402. https://doi.org/10.1126/science.354.6311.401
https://www.science.org/doi/10.1126/science.354.6311.401
※本稿は2020年発表の記事 『温度上昇の予測は「チューニング」されている』 に加筆・修正したものです。