

| 本稿は、NETZEROWATCHから許可を得て以下を邦訳したものである。 https://www.netzerowatch.com/climate-models-behind-net-zero-policies-are-thoroughly-flawed/ |
著者について
ウィリス・エッシェンバックは60年以上にわたってコンピュータのプログラミングに携わっており、また気候変動について10年以上執筆活動をしている。
謝辞
本稿は、wattsupwiththat.comに掲載された記事をもとにしており、Net Zero Watchはアンソニー・ワッツに再掲載の許可を得たことに感謝する。
1.はじめに
多くの気候モデルと同様、NASAのGISSモデルEは、開発開始前に設計されたものではない。むしろ何十年にもわたって、新しいパーツの追加、問題点の修正、新たな問題を解決するための暫定的な変更など、付加的に発展してきたのである。メインプログラマーの一人であるギャビン・シュミットは、モデルEを説明する論文で以下のように書いている:
「気候モデルの開発とは、細かな追加や修正と、時折行われる特定の部分の全面的な入れ替えを組み合わせた継続的なプロセスにほかならない1。」
さらに厄介なのは、このようなプログラムの多くがそうであるように、これがFORTRANというコンピュータ言語で書かれていることだ。これは、このモデルが生まれた1983年には最適な選択だったが、2023年の現在では恐ろしく使いにくい言語なのである。
この40年間で、このコードはどれだけ増えたのだろうか?補助ファイルを除くと、FORTRANコード自体は441,668行に達している。その結果、スーパーコンピュータでしか実行できなくなった。以前にこのコードを見たのは20年前だったが、2022年になって、どのように変わったのか、もう一度見てみようと思いたった。
2.安定性と不安定性
現代の気候モデルは、気候システムの驚くべき安定性を再現するのに苦労している。モデルは「反復的」である。つまり、ある時間ステップの出力が次の時間ステップの入力として使われる。その結果、過去の時間ステップJの出力の誤差は、次の時間ステップKの入力の誤差として引き継がれ、無限に繰り返される。このため、モデルが「スノーボール・アース(全球凍結)」に陥ることや、オーバーヒートして仮想惑星が燃え上がってしまうということが非常に起こりやすくなる。図1は、ある気候モデルを数千回実行した例である。
図-1の上の図では、コントロール・フェーズ(訳注:CO2濃度を一定にした計算の意)においてどれだけ数多くコースからはずれているかに注目してほしい。実際の地球ではこのようなことは起こらない。
このように気候モデルが「コースから外れ」、現実から離れてしまうのを防ぐために、プログラマーはまずその物理モデルのどこが間違っているのかを突き止め、それを修正する必要がある。しかし、私が20年前にモデルEのコードを初めて見たとき、NASAのチームが非常におかしなことをしている箇所を見つけたのだ。
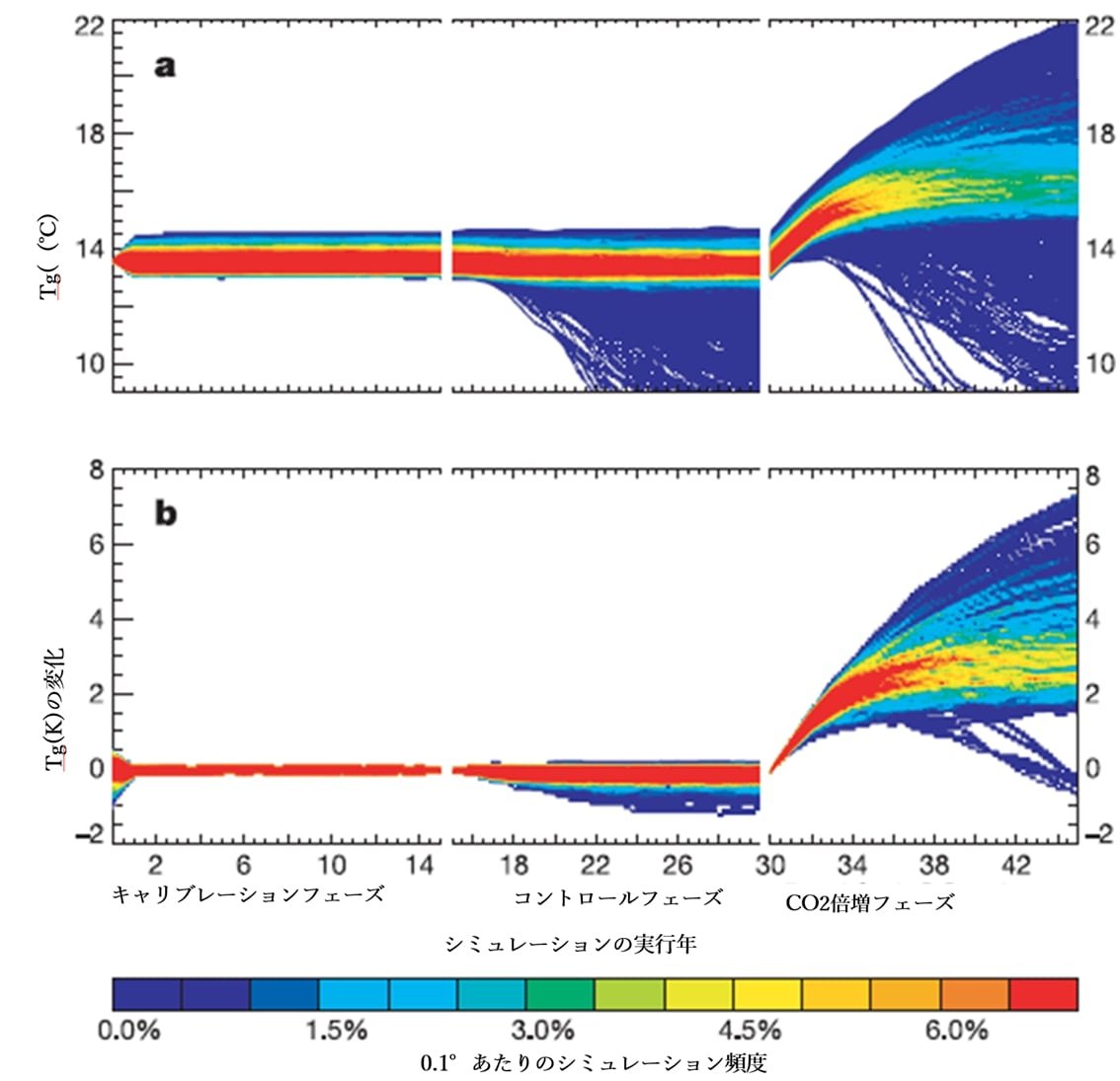
図1:シミュレーションの3つのフェーズにわたる地球の平均気温Tgの頻度分布(色分けは0.1K間隔あたりの軌跡の密度を示す)。
a.2,017の独立したシミュレーションの頻度分布。
b.414のモデルのバージョンにおける頻度分布。bでは、Tgはキャリブレーションフェーズ終了時の値に対する相対値で示され、初期条件アンサンブルメンバーが存在する場合は、各々の時点における平均値をとっている。
3.上下限の設定
ポリニヤとは、極地の季節的な海氷の上に形成される雪解け水の開水面あるいは薄氷域のことである。これは海氷の反射率(専門用語で「アルベド」)を計算する上で重要な要素であり、太陽から入ってくる熱をどれだけ上空へ反射させるかを決める重要な要素である。モデルEを初めて見たとき、ポリニヤが大きな問題であることがわかった。モデルは、ポリニヤが毎年あまりにも多くの期間、海氷上に存在していることを示唆していたのだ。モデルにおいて本質的にあまりにも気温設定が高すぎたのだ。しかし、その原因を解明するのではなく、雪解け水の溜まり場が形成される日数に厳しい時間制限を加えただけだった。
現在のコードを見ると、その部分に手を加えたようだ。というのも、日数の制限を作ったルーチンはもう見つからないからだ。その代わりに、海氷(sea ice albedo)と雪解け池(melt pond albedo)のアルベド値に限界を設定する新しいサブルーチンがある。また、海氷上の湿った雪と乾いた雪のアルベド(反射率)(wet, dry snow albedo)も定数で指定している。最後に、可視光(VIS)と近赤外(NIR1-5)の5つの帯域の上下限と値も指定している。興味のある方のために、コードをコードブロックAに示す(行中の’c’または’!’はコメントを表す)。
つまり、海氷のアルベドを計算するコードがあるのだが、そのコードが非現実的な出力を出すことがあるのだ。しかし、NASAのチームはその原因を突き止め、問題を修正するのではなく、ただ単に不適切な値に対して上限値や下限値に置き換えているのだ。まさに科学の極致だ!(訳注:嫌味で言っている)

わかりやすく言えば、「気温が-10℃以下で、ポリニヤが再凍結していなければ、再凍結させろ」ということだ。このコードがなければ、どんなに寒くても融解池の一部は再凍結しないかもしれない!これが、気候モデラーが自分たちのモデルが「物理ベース」だと言うときの本当の意味である(訳注:嫌味)。ハリウッドのプロデューサーが映画を「実話に基づいている」と言うのと同じように、彼らはこの言葉を使うのだ。
コードブロックC(これは誰にでも理解できる平易な英語に近いものとなっている)は、モデルEコードにおけるもうひとつの素晴らしいコメントと言える(訳注:嫌味)。

言い換えれば、もし気温が異常値を示したら…その原因を調べたり、直したりしてはいけない。適正な温度に設定して そのまま続けよ、ということだ。
では、妥当な温度とは何度なのだろうか?結局のところ 前のタイムステップの温度に設定し、それを続けるだけ。いわゆる物理学ってやつだ(訳注:嫌味)。次のコードブロックDは別のものだ。

またしても、気候モデルはレールから脱線してしまっている: 風が時速500マイルで吹いているのだ。しかし、その理由を探すことはしない。ただレールに押し戻し、そして… そのまま計算を続けるのだ。
4.チューニング
チューニングに用いるパラメーターは、まったく非物理学的なものだ。以下は、先に引用したギャビン・シュミットの論文からの説明である:
「モデルは、コントロールランシミュレーションにおいて、全球的な放射平衡(すなわち、[大気上部の]正味放射がゼロから±0.5 W m-2 以内)と妥当な値の惑星アルベド(29%から31%の間)になるように調整(氷雲と水雲の発生開始のための相対湿度の閾値を使用して)されている。」
わかりやすく訳すと、このモデルでは、太陽から入ってくる熱と宇宙空間に逃げていく熱とが平衡にならないため、モデル内の仮想地球はオーバーヒートするか、雪だるまになるかのどちらかである。その解決策は、平衡に達するまでモデルの奥深くに埋もれているパラメーターを調整することである。チューニング・ノブ(つまみ)を回すだけでいい!すべてうまくいくのだ!
実際、チューニング・ノブは非常にうまく機能したので、彼らはさらに2つ…さらにもう1つの上限値(コードブロックEを参照)を追加した:

すべてのモデルは、私が「進化的チューニング」と呼んでいるもの、つまり、変更を加え、そのモデルを唯一のテスト対象である過去の記録と照らし合わせてテストするプロセスにかけることになる。モデルが過去の記録をよりよく再現できるようになれば、その変更は維持される。しかし、もしその変更によって「ハインドキャスト(過去を再現すること)」の結果が悪くなれば、その変更は捨てられるのである。
残念なことに、アメリカの証券会社の広告に、「過去の実績は将来の成功を保証するものではない」と述べるべきと法律で定められているように、気候モデルがハインドキャスト(過去を再現すること)できるという事実は、そのモデルが未来をうまく予測できるかどうかについては、まったく何の意味もなさない。特に、モデルが上限値の設定と調整可能なパラメーターによって破綻しないように支えられ、さらに過去を再現するように進化的に調整されている場合はなおさらだ…。
5.その他
さて他には何が起こっているのか?このような場当たり的なプロジェクトにありがちなことだが、モデルEチームは一つの変数名を使って、プログラムの異なる部分で二つの異なるものを表現することになってしまった、 これは問題かもしれないし、そうでないかもしれないが、だがしかし、これは目に見えないバグにつながる危険なプログラミングのやり方であると言える(FORTRANは’大文字と小文字を区別しない’ので、’ss’は’SS’と同じ変数であることに注意して欲しい。プログラマーがプログラムの異なる部分で両方を使うことを止めることはできないが、これは非常に望ましくないことである)。以下のコードブロックFでは、このような重複した変数名のいくつかが示されている。

最後に、モデルがエネルギーと質量の保存に失敗するという問題がある。コードブロックGは、この問題を処理する1つの例を示している。
不思議なことに、サブルーチン’addEnergyAsDiffuseHeat’はプログラムの異なる部分で2回定義されている…おっと話を元に戻す。エネルギーが保存されない場合、このコードで実行されるのは、単純に差分を取り、それを世界中に均等に広げることである。そもそもこのようなサブルーチンが必要なのは、コンピュータが一定の精度しか持たないからである。丸め誤差は避けられない。使われている方法は決して不合理なものではない。しかし、20年前、私はギャビン・シュミットに、このサブルーチンに、エネルギー不均衡がある閾値より大きくなった場合にプログラムを停止させる「マーフィー計」のようなものがあるかどうか尋ねたことがある (マーフィー計は、ユーザーが設定した値を超えた場合にアラームを出すもので、図2を参照)。このような計りがなければ、モデルは誰にも気づかれずに大量のエネルギーを得たり失ったりする可能性がある。ギャビンは、エネルギーの不均衡が大きすぎる場合にプログラムを停止させるアラームはないと言った。それで私は、アンバランスの大きさは通常どのくらいなのか聞いてみた。彼はわからないと言った。


図2:マーフィー計
そこで、20年後のコードをもう一度見直して、そのような「マーフィー計」を探したのだが…見つからなかった。サブルーチンの’addEnergyAsDiffuseHeat’とその周辺を探したし、 「energy」、「kinetic」、「potential」、「thermal」といったキーワードも探してみた。さらに実行を停止するFORTRAN命令「STOP」と「STOP_MODEL」命令も探した。 これらは特定の条件下でモデルの実行を停止し、診断エラーメッセージを出力するサブルーチンである。
モデルEでは、水のない湖、ファイルの問題、「質量診断エラー」、「圧力診断エラー」、太陽天頂角が[0.0から1.0]の範囲にないこと、無限ループ、海洋変数の上下限超えなど、あらゆることに対して846回の「STOP_MODEL」呼び出しがある。あるSTOP_MODELコールは、実際に’Please double-check something or another’と出力する。一方、個人的に気に入っているのは、’negative cloud cover(負の雲被覆)’または’negative snow depth(負の積雪)’があったときに停止を求めるものだ。実際にはそういうことが起きるとうんざりするのだが…。(訳注:物理的にありえない)。
そして、これはすべて非常に良いことなのだ。これらはマーフィー計であり、モデルがレールから外れたときに止めるように設計されているもので、このようなモデルの重要かつ必要な部分である。しかし、エネルギーの過不足分を地球上に均等に撒き散らすサブルーチンについては、マーフィー計が見当たらなかった。公平を期すため言うと、441,668行のコードがあり、コメントも非常に乏しい…。というわけで、そこにあったのかもしれないが、探し出すことはできなかった。
6.結論
私が初めてコンピュータ・プログラムを書いたのは半世紀以上も前のことで、それ以来、数え切れないほどのプログラムを書いてきた。今私のコンピュータには、R言語で書いた2000以上のプログラムがあり、その総コード行数は23万行を超える。話せる言語よりも忘れてしまったコンピュータ言語の方が多いが、C/C++、Hypertalk、Mathematica(3言語)、VectorScript、Basic、Algol、VBA、Pascal、FORTRAN、COBOL、Lisp、LOGO、Datacom、Rに堪能で、WattsUpWithThatのウェブサイトに書いた1,000本程度の記事のコンピュータ解析はすべて私が行った。カードゲームのブラックジャックのプログラムのテストから、80フィートの鋼鉄製漁船3隻のパーツを切断するためのCAD/CAMファイルの提供、住宅建築の入札システム、15メートルのカテナリーテントを切断して組み立てるためのパターン作成、そして…そう、今日書いたGISSモデルE気候モデルのコード内のキーワードを検索するプログラムまで、あらゆるプログラムを書いてきた。というわけで、プログラミングに関しては、自分でもよく分かっている。
次にモデルについて。私の中では、モデルをシングルパス(単一過程)・モデルと反復モデルの2種類に区別している。シングルパス・モデルは、さまざまな入力を受け取り、それに対していくつかの操作を行いそしていくつかの出力を生成する。一方、反復モデルは、さまざまな入力を受け取り、それに対して何らかの操作を行い、何らかの出力を出すが、シングルパス・モデルとは異なり、 その出力を次の反復の入力として使用する。このプロセスを何度も繰り返して、最終的な答えを出す。
反復モデルにはいくつかの大きな課題がある。第一に、前述したように、反復モデルは一般的に繊細で壊れやすい。これは、出力の誤差が入力の誤差となり、不安定になるからだ。前述したように、これを修正するには2つの方法がある。コードを修正するか、レールを外れないようにガードレールを設けるかだ。正しい方法は、修正することだ…これが2つ目の課題につながる。
第二の課題は、反復モデルは非常に不透明だということだ。気象モデルと気候モデルは反復的である。気候モデルは通常、30分単位で動いている。つまり、気候モデルが例えば50年先を予測する場合、コンピュータは1日あたり48ステップを踏むことになる。コンピュータは、1日48ステップ×1年365日×50年、つまり876,000回の繰り返し計算を行うことになる。その状況の中で意味のない、あるいは物理学を無視した答えが出たとしたら、どこで道を踏み外したのかどうやって突き止めればいいのだろうか?
私はGISSモデルを非難しているのではないことをご理解いただきたい。このような同じ問題は、大なり小なり、すべての大規模で複雑な反復モデルにも存在する。私が指摘しているのは、これらのモデルは “物理学ベース “ではなく、墜落しないように支えられ、柵で囲まれているものである、ということなのだ。
結論として言えば、半世紀にわたるプログラミングと数十年にわたる気候研究によって、私はいくつかのことを学んだ:
- コンピュータモデルができることは、プログラマーの理解不足を・・もっと重要なことに誤った理解を・・可視化し、美化することだけだ。もし、CO2が気温をコントロールしていると信じてモデルを書いたとしたら…… いったいどのような結果になるか推測してください?
- 言語学の意味論の研究者アルフレッド・コージブスキーの有名な言葉に「地図は領土ではない」というものがある。コージブスキーは、人々がしばしば現実のモデルと現実そのものを混同してしまうという考えを詩的に表現するためにこの言葉を使った。気候モデラーたちはこの問題を抱えており、自分たちの結果をあたかも現実世界の事実であるかのように論じることがあまりにも多い。
- 気候は、これまで私たちがモデル化を試みてきた中で、圧倒的に最も複雑なシステムである。それは大気圏、生物圏、水圏、岩石圏、雪氷圏、電気圏という少なくとも6つのサブシステムを含んでいる。これらすべてに内部反応、様々な物理的な力、共鳴、サイクルがあり、他のすべてと相互作用している。このシステムは、内と外の両方から様々な力を受けている。気候に関する私の第一法則によれば、「気候においては、すべてのものは他のすべてのものとつながっている。そうでないときを除いては…」のである。
- 気候のモデル化はまだ始まったばかりである。
- 反復モデルは信用できない。恐らくずっと。そう、現代の飛行機は反復モデルを使って設計されている…しかし、設計者は今でも風洞を使って結果をテストしている。残念なことに、気候に関しては “風洞 “に相当するものは何もない。
- バグの多いコンピュータ・コードの第一法則は、バグを一つつぶすと、おそらく他のバグを二つ作ってしまうということだ。
- 複雑さは信頼性ではない しばしば複雑なモデルよりも単純なモデルの方が良い答えを出す。
では結論は?現在のコンピュータ気候モデル(本当は “気候混迷モデル(climate muddles) “と呼ぶべきだが)は、公共政策を決定するために使われるにはほど遠い。このことを証明するには、これらのモデルが生み出した、誤り、失敗し、墜落し、炎上した数々の予測を見ればいい。そんなものに注意を払う必要はない。「物理学ベース」ではないし(ハリウッド的な意味ではそうであるが)、ゴールデンタイムに出演するような段階からはほど遠い。気候モデルの主な用途は、プログラマーの非現実的な恐怖に偽りの正統性を加えることくらいだ。
<注釈>
1.https://journals.ametsoc.org/view/journals/clim/19/2/jcli3612.1.xml.