メディア掲載 グローバルエコノミー 2012.03.02
超大量多様な経済データを科学的に実証分析!その実態とは?

海外のヘッジファンドでは、資産運用のため、さらなるアルゴリズムモデル等の強化を進めている。 より多くの収益機会を獲得するという狙いのもと、 膨大な過去のティックデータだけでなく、損益計算書やニュースフィードも取り込んだシミュレーションや統計分析、パターン分析などから、潜在的かつ微かな利益機会のシグナルを感知する動きを拡大させている。この背景には、大量の金融データを用いて、何百回・何千回もの分析を高速で行い、「何か」の傾向を分析しているようだ。 本コラムは「損失回避と収益向上のための取引戦略のあり方」を命題として、大量データの分析で一体何ができるのか、またデータを分析することで、どんな傾向が見えてくるのかを日本で膨大な経済データを分析している物理学者であるキヤノングローバル戦略研究所の大西立顕主任研究員にお話をお伺いした。
大規模な経済データをどうして分析するのでしょうか?
経済現象は経済学者が研究している分野ですが、近年、物理学や数理工学の研究者も大規模な経済データを分析し研究するようになってきています。金融市場の分野では価格の取引1つ1つが完全に電子データとして取れるようになったのは、ここ10年や20年の話です。このデータを使うことで、数百万や数千万といった大規模なデータを用いた科学的な分析ができるようになりました。
近年のコンピュータの計算能力の向上も無視できません。昔は膨大なデータを扱う計算は難しかったのですが、ここ10年に至っては、数百万程度のデータは簡単に処理できるようになり、分析が可能になったという背景があります。
大きなデータを使うと、何がメリットになるのでしょうか?
たとえば、6/10と、6,000/10,000という数値を比較してみましょう。 どちらも「0.6」となるので、値としては同じなのですが、統計的な数値としては意味が異なります。たとえば、10人のうち6人が賛成の場合、60%なので過半数の賛成になりますが、誤差を考えると10人だと信頼性が低いため、「0.6±0.30」となります。「±0.30」が信頼性に関係するところで、これは母集団の数によって決まってくるというのが統計学の考え方です。それが10,000人になってくると、その誤差が「±0.01」にまで小さくなります。「0.5」より大きいか、小さいかということがとても大きな意味を持つ問題では、その2つの結果には決定的な違いがあります。6/10が0.5より大きいか小さいか聞かれると、それはちょっとわからないということになります。なぜかというと、「0.3」も誤差があるので、はっきりと断言することはできなくなるからです。しかし、その誤差が「0.01」まで小さくなると、0.5より確実に大きいと断言することができます。

数値としては同じ。しかし、統計的な数字としては意味が異なる
大きなデータを使うことによって、統計的な精度をより高めることができるのです。たとえば、価格変動がランダムかどうかを検定する場合においては、こういった差は相当大きく、0.5より大きいか小さいかの微妙なところが問題になるので、大きな意味をもってくるのです。
つまり、経済学で用いられてきた小規模なデータではなく、超大規模なデータを使った分析をすることで、データの持つ統計性を厳密に吟味できるようになり、これまで分析できなかったような経済事象について、新たな重要な知見が得られる可能性があるのです。
電子化が進んだことによって、これまで全く調べることができなかった事柄も研究されるようになってきています。株価の変動でも需要と供給がどのくらいあって、それによって、価格がいくら変動するかということが、昔はほとんど調べることはできなかったのですが、今では市場の取引データを全て見ることができるようになってきたので、厳密に調べられるようになりました。
経済学では仮説や仮定を出発点にして理論が構築されてきたのですが、今では実際のデータを使って厳密にそれらが正しいかどうか確認することができるようになりました。そして、それをもとにしてより現実的な理論を作ることもできるようになってきています。
物理学者は経済事象をどのように見ていますか?
多くの場合、統計学や経済学では正規分布を前提として考えますが、現実は違っています。
市場価格の変動を表すもう1つの分布として「ベキ分布」があります。統計学や経済学で明らかにされているほとんどの事象は、「正規分布」を前提にしています。これは、たとえば一般的な身長は1~2メートル程度であり、10センチの人や10メートルの人は存在しません。また一般的な靴のサイズは20~30センチであり、2センチの人や2メートルの人はいないといった分布です。
「平均値±標準偏差」程度の平均的なスケールがあり、大きく外れた値が出にくい事象に関しては平均値のみに注目すれば十分で、数学的にも扱いやすくなります。これが、正規分布が統計手法の前提になっている理由の1つです。しかし現実の市場価格の変動を見てみると、正規分布には当てはめることができない事象がたくさんあります。
その1つに「フラクタル性」があります。たとえば、過去13年間の価格変動のグラフの一部を拡大した1年間のグラフと、その1年間の1部を拡大した1カ月のグラフ、さらにその1カ月のグラフの1部を拡大した1日のグラフ、すべてが同じような形のグラフになっているようにみえます。
フラクタル性とは、クッキーを砕いた場合に、数個の大きな破片と無数の小さな破片に分かれ、その小さな破片を拡大すると、同じく数個の大きな破片と無数の小さな破片に分かれるという、どのスケールで見ても同じ構造になるという性質です。この性質を統計的に表したものが「ベキ分布」なのです。
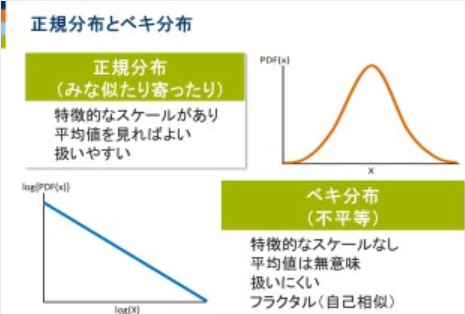
正規分布とベキ分布
たとえば、企業の売上高は、1000万円以上の企業が1万社あるとすると、1億円以上が1000社、10億円以上が100社、100億円以上が10社存在するようなベキ分布になることが知られています。ごくごく少数の一握りの企業は桁違いに売上高が大きいけれど、圧倒的大多数の企業は桁違いに売上高が小さいため、90%以上の企業は平均値以下の売上高であり、特徴的なスケールはなく、平均値は無意味になります。これをグラフにすると、恐竜のようにみえます。つまり、恐竜の頭に位置する売上高の小さい企業がとてもたくさん存在し、尻尾の先の方に対応する売上高の大きい企業はどんどん少なくなっていきます。しかしながら、尻尾の先はどこまでも限りなくずっと伸びているので、「ロングテール」と呼ばれています。
物理学者が経済を分析する場合には、大規模なデータを使って、正規分布ではなくて、ベキ分布している現象として扱っています。
コンピュータ技術の必要性をお教えください。
超大規模なデータを分析するためには、正規分布を前提としている平均値や分散、相関係数、回帰分析などの一般的な統計手法は利用することができず、ノンパラメトリック法(順位相関、連検定など)やランダムシャッフル(モンテカルロ法)など、ベキ分布のための計算手法が有効になります。こういった計算をする場合、その計算量が膨大となります。
ここで物理と経済の大きな違いについて少しご紹介します。
物理現象においては、100回同じことを行えば、100回同じ結果が返ってきます。しかし経済現象においては、状況が常に変化しているために、非定常性が存在しており、100回同じことを行っても、100回同じ結果が返ってきません。この非定常性を前提としてきちんと分析するには、状況に応じて時期を区分した細かな分析が必要になってきます。
こういったベキ分布や非定常性を考慮した分析では、超大規模なデータを使用して、膨大な計算を繰り返さなければなりません。そこでは、最先端のコンピュータ技術を使用して、超膨大なデータを超高速に処理する必要がでてきます。
このような超大量、超多様な経済データの科学的な分析により、これまでの伝統的な経済学では分析できないような経済事象を明らかにすることが可能になっています。
数理科学と経済学の知見を融合することで、経済現象のメカニズムを解明し、現実的な理論を構築することができます。これにより、迅速かつ正確に経済の実態を把握し、効果的な制度や政策の提言に生かすことが期待されています。